|
Box-Cox Transformations
Author(s)
David Scott
Prerequisites
This section assumes a higher level of mathematics background than most other sections of this work. Additional Measures of Central Tendency (Geometric Mean), Bivariate Data, Pearson Correlation, Logarithms, Tukey Ladder of Powers
George Box and Sir David Cox collaborated on one paper (Box, 1964). The story is that while Cox was visiting Box at Wisconsin, they decided they should write a paper together because of the similarity of their names (and that both are British). In fact, Professor Box is married to the daughter of Sir Ronald Fisher.
The Box-Cox transformation of the variable x is also indexed by λ, and is defined as
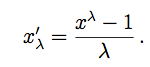 (Equation 1) (Equation 1)
At first glance, although the formula in Equation (1) is a scaled version of the Tukey transformation xλ, this transformation does not appear to be the same as the Tukey formula in Equation (2). However, a closer look shows that when λ < 0, both xλ and x′λ change the sign of xλ to preserve the ordering. Of more interest is the fact that when λ = 0, then the Box-Cox variable is the indeterminate form 0/0. Rewriting the Box-Cox formula as
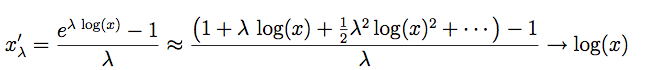
as λ → 0. This same result may also be obtained using l'Hôpital's rule from your calculus course. This gives a rigorous explanation for Tukey's suggestion that the log transformation (which is not an example of a polynomial transformation) may be inserted at the value λ = 0.
Notice with this definition of 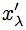 that x = 1 always maps to the point = 0 for all values of λ. To see how the transformation works, look at the examples in Figure 1. In the top row, the choice λ = 1 simply shifts x to the value x−1, which is a straight line. In the bottom row (on a semi-logarithmic scale), the choice λ = 0 corresponds to a logarithmic transformation, which is now a straight line. We superimpose a larger collection of transformations on a semi-logarithmic scale in Figure 2. that x = 1 always maps to the point = 0 for all values of λ. To see how the transformation works, look at the examples in Figure 1. In the top row, the choice λ = 1 simply shifts x to the value x−1, which is a straight line. In the bottom row (on a semi-logarithmic scale), the choice λ = 0 corresponds to a logarithmic transformation, which is now a straight line. We superimpose a larger collection of transformations on a semi-logarithmic scale in Figure 2.
Transformation to Normality
Another important use of variable transformation is to eliminate skewness and other distributional features that complicate analysis. Often the goal is to find a simple transformation that leads to normality. In the article on q-q plots, we discuss how to assess the normality of a set of data,
x1,x2,...,xn.
Data that are normal lead to a straight line on the q-q plot. Since the correlation coefficient is maximized when a scatter diagram is linear, we can use the same approach above to find the most normal transformation.
Specifically, we form the n pairs
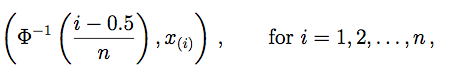
where Φ−1 is the inverse CDF of the normal density and x(i) denotes the ith sorted value of the data set. As an example, consider a large sample of British household incomes taken in 1973, normalized to have mean equal to one (n = 7125). Such data are often strongly skewed, as is clear from Figure 3. The data were sorted and paired with the 7125 normal quantiles. The value of λ that gave the greatest correlation (r = 0.9944) was λ = 0.21.
The kernel density plot of the optimally transformed data is shown in the left frame of Figure 4. While this figure is much less skewed than in Figure 3, there is clearly an extra "component" in the distribution that might reflect the poor. Economists often analyze the logarithm of income corresponding to λ = 0; see Figure 4. The correlation is only r = 0.9901 in this case, but for convenience, the log-transform probably will be preferred.
Other Applications
Regression analysis is another application where variable transformation is frequently applied. For the model
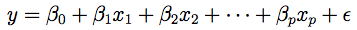
and fitted model

each of the predictor variables xj can be transformed. The usual criterion is the variance of the residuals, given by
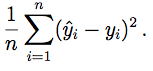
Occasionally, the response variable y may be transformed. In this case, care must be taken because the variance of the residuals is not comparable as λ varies. Let  represent the geometric
mean of the response variables. represent the geometric
mean of the response variables.
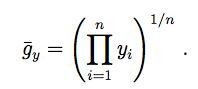
Then the transformed response is defined as
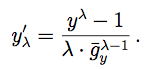
When λ = 0 (the logarithmic case),
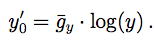
For more examples and discussions, see Kutner, Nachtsheim, Neter, and Li (2004).
References
Box, G. E. P. and Cox, D. R. (1964). An analysis of transformations, Journal of the Royal Statistical Society, Series B, 26, 211-252.
Kutner, M., Nachtsheim, C., Neter, J., and Li, W. (2004). Applied Linear Statistical Models, McGraw-Hill/Irwin, Homewood, IL.
Please answer the questions:
|