|
Differences between Means
Author(s)
David M. Lane
Prerequisites
Sampling
Distribution of Difference between Means, Confidence
Intervals, Confidence Interval on the
Mean
Learning Objectives
- State the assumptions for computing a confidence interval on the difference
between means
- Compute a confidence interval on the difference between means
- Format data for computer analysis
It is much more common for a researcher to be
interested in the difference between means than in the specific
values of the means themselves.
The difference in sample means is used to estimate
the difference in population means. The precision of the estimate
is revealed by a confidence
interval.
In order to construct a confidence interval, we
are going to make three assumptions:
- The two populations have the same variance. This assumption
is called the assumption of homogeneity of
variance.
- The populations are normally
distributed.
- Each value is sampled independently
from each other value.
The consequences of violating these assumptions
are discussed in a later section. For now, suffice it to say that
small-to-moderate violations of assumptions 1 and 2 do not make
much difference.
A confidence interval on the difference between
means is computed using the following formula:
Lower Limit = M1 -
M2 -(tCL)(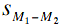 ) )
Upper Limit = M1 - M2
+(tCL)()
where M1 - M2
is the difference between sample means, tCL
is the t for the desired level of confidence, and
is the estimated standard
error of the difference between sample means.
The first step is to compute the estimate of the
standard error of the difference between means ().
Recall from the relevant
section in the chapter on sampling distributions that the
formula for the standard error of the difference in means in the
population is:
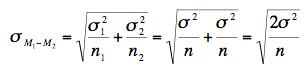
In order to estimate this quantity, we estimate
σ2 and use that estimate in place
of σ2. Since we are assuming the
population variances are the same, we estimate this variance by
averaging our two sample variances. Thus, the estimate of variance
is computed using the following formula:

where MSE is the estimate of σ2.
=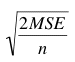
The next step is to find the t to use for the
confidence interval (tCL). To calculate
tCL, we need to know the degrees
of freedom. The degrees of freedom is the number of
independent estimates of variance on which MSE is based. This
is equal to (n1 -1) + (n2
-1) where n1 is the sample size for the
first group and n2 is the sample size
of the second group.When n1= n2,
it is conventional to use "n" to refer to the sample
size of each group.
Online:
Calculator: Find t for confidence interval
Please answer the questions:
|